
大数据时代
大数据定义
大数据是指:利用常用软件工具捕获、管理和处理数据所耗时间超过可容忍时间的数据集
- 体量巨大
- 类型繁多
- 价值密度低
- 处理速度快
大数据处理与传统数据处理的差异
| 大数据处理 | 传统数据处理 | |
|---|---|---|
| 数据规模 | 大(以GB、TB、PB为单位) | 小(以MB为单位) |
| 数据类型 | 繁多(结构化、半结构化、非结构化) | 单一(结构化为主) |
| 模式和数据的关系 | 先有模式后有数据,模式随数据增多不断演变 | 先有数据() |
| 处理对象 | “大海中的鱼”,通过某些“鱼”判断其他种类的“鱼”是否存在 | “池塘中的鱼” |
| 处理工具 | No size fits all | One size fits all |
大数据计算任务
计算任务分类
IO密集型任务
- 涉及网络,磁盘,内存 IO 的任务
- CPU消耗少,任务大部分时间在等待IO操作中完成(因为CPU和内存速度远大于IO速度)
- 任务越多,CPU效率越高,大部分应用都是IO密集型任务,如Web应用
- 提升IO密集型任务的效率,主要是提升网络传输效率和读写效率
计算密集型任务
- 消耗CPU资源进行大量计算。如圆周率,视频高清解码
- 任务越多,效率越低(时间花在切换任务上)。同时进行的最大任务数量等于CPU核心数
- 主要消耗CPU资源,代码运行效率至关重要
数据密集型任务
- 大量独立的数据分析处理作业可以分布在松耦合的计算机集群系统的不同节点上运行
- 海量数据I/O吞吐需求
- 大部分数据密集型应用都有个数据流驱动的流程
- 典型应用主要为三类:日志分析、Saas应用、大型企业商务智能应用
大数据应用的主要计算模式
- 批处理计算(MapReduce、Spark等)
- 流计算(Spark、Storm、Flink、Flume、Dstream等)
- 图计算(GraphX、Gelly、Giraph、PowerGraph等)
- 查询分析计算(Hive、Impala、Dremel、Cassandra等)
Hadoop 大数据生态圈

传统数据处理面临的挑战
传统框架:小型机+磁阵+商用数据仓库
传统数据处理的弊端
- 海量数据的高存储成本
- 批处理性能不足
- 流式数据处理缺失
- 有限的扩展能力‘单一数据源
- 有限的扩展能力
- 数据资产对外增值
面临的挑战
- 业务部门无清晰的大数据需求
- 企业内部数据孤岛严重
- 数据可用性低,质量差
- 数据相关管理技术和架构
- 数据安全问题
- 大数据人才缺乏
- 数据开放与隐私的权衡
机遇
- 大数据挖掘成为商业分析的核心
- 大数据成为信息技术应用的支撑点
- 大数据成为信息产业持续增长的新引擎
HDFS分布式文件系统&Zookeeper
HDFS概述及应用场景
概述
- 分布式文件系统(HDFS)是一种旨在商品硬件上运行的分布式文件系统
- 具有高度容错能力,部署在低成本硬件上
- 提供对应用程序数据的高吞吐量访问,适用于具有大数据集的应用程序
- 放宽了Linux的POSIX要求,以实现对文件系统的流式访问
- 最初是作为Apache Nuthch Web搜索引擎项目的基础结构而构建的
- 是Apache Hadoop Core项目的一部分
应用场景
- 网站数据
- 交通电子眼数据
- 气象数据
- 传感器数据
不适用场景
- 实时响应数据
- 小文件(元数据占比150KB,小文件过多元数据占用空间过大)
- 多用户写场景、随机写场景(HDFS写入是追加到文件的末尾)
HDFS相关概念
HDFS架构
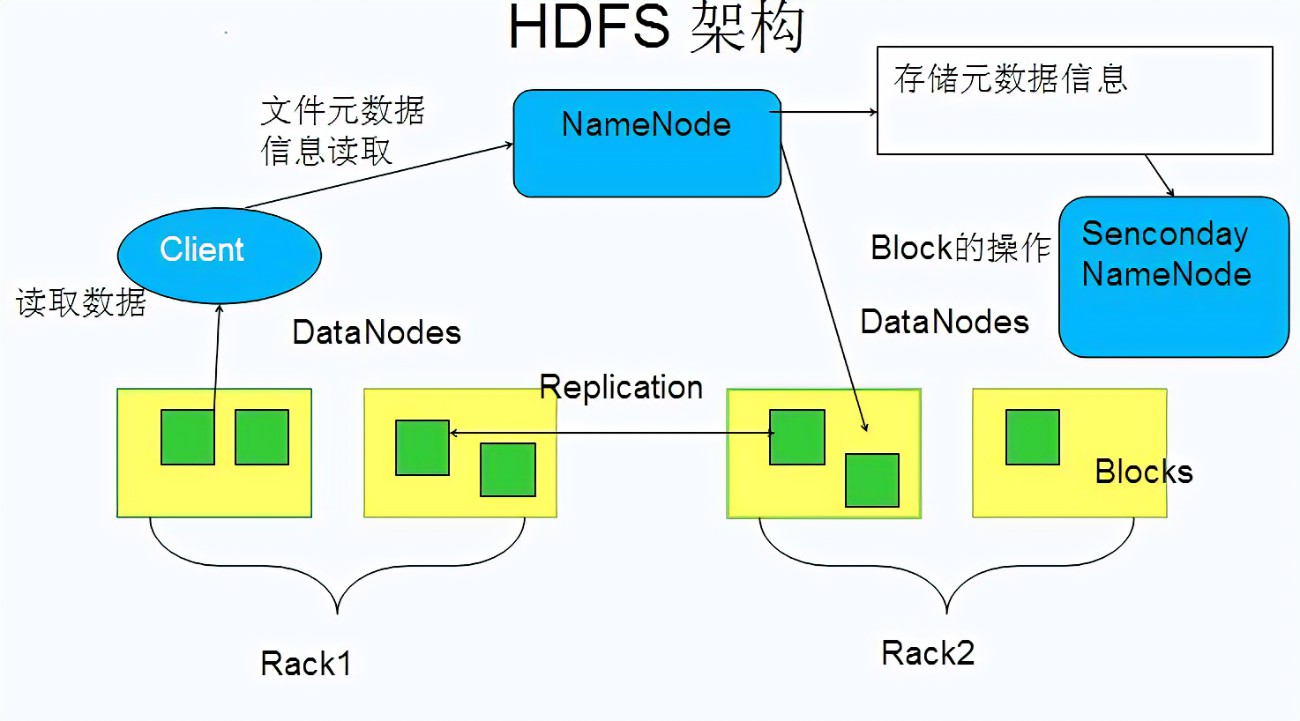
Block-块
- 默认一个块128MB,一个文件被分为多个块,以块为存储单位
- 块远大于普通文件系统,可以最小化寻址开销
- 支持大规模文件村塾、简化系统设计、适合数据备份
NameNode和DataNode
| NameNode | DataNode |
|---|---|
| 存储元数据在内存中 | 存储文件在磁盘 |
| Block与DataNode之间映射关系 | 维护block id 到 Datanode 的映射关系 |
命名空间管理
- 命名空间包含目录、文件、块
- 使用传统的分级文件系统,因此可以像操作普通文件系统一样操作HDFS文件系统
- NameNode 记录所有的操作和更改
通信协议
HDFS是一个部署在集群上的分布式文件系统,因此很多数据需要通过网络进行传输
- 所有通信协议都是构建在TCP/IP协议基础之上的
- 客户端通过一个可配置端口向名称节点主动发起TCP连接,并使用客户端协议与 NameNode 进行交互
- NameNode 与 DataNode 之间则使用数据节点协议进行交互
- 客户端与 DataNode 的交互通过 RPC(Remote Procedure Call)实现。在设计上,NameNode 不会主动发起 RPC,而是响应来自客户端和 DataNode 的 RPC 请求
客户端
- 客户端是用户操作 HDFS 最常用的方式,HDFS 在部署时都提供了客户端
- HDFS 客户端是一个库,包含 HDFS 文件系统接口,这些接口隐藏了大部分复杂的实现
- 支持读写等常用操作,提供类似 Shell 命令行的方式访问 HDFS 中的数据
- 提供 Java API,作为应用程序访问文件系统的接口
HDFS 局限性
HDFS 只设置唯一一个NameNode,虽然大大简化了设计,但是也带来了局限性
- 命名空间的限制:NameNode 保存在内存中,受到内存大小的限制
- 性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个 NameNode 的吞吐量
- 隔离问题:集群中只有一个 NameNode,无法对不同的应用程序进行隔离
- 集群的可用性:一旦这个 NameNode发生故障,整个集群变得不可用
HDFS 关键特性
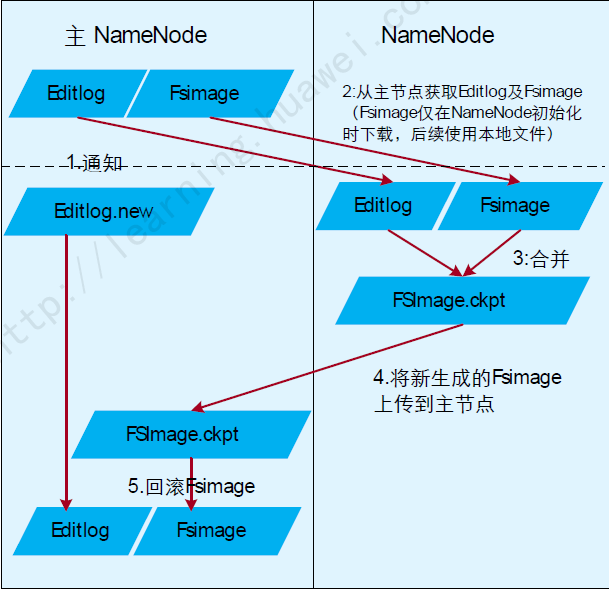
高可用性(HA )
HDFS 2.0 新增备用 NameNode,以提高可用性

元素据持久化
右边为 SecondaryNameNode,不是 StandyNameNode
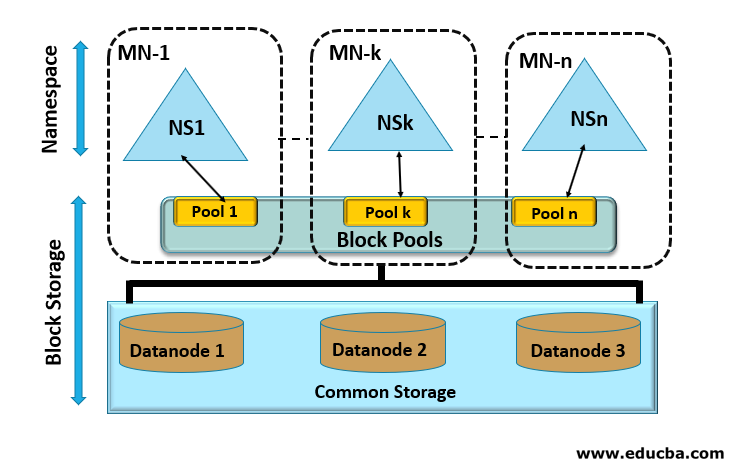
HDFS 联邦(Federation)
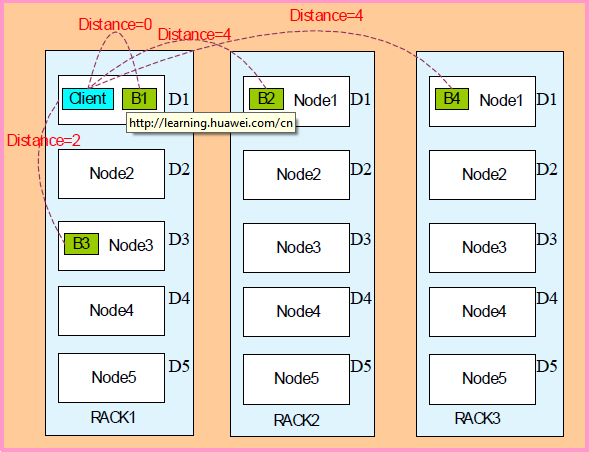
数据副本机制
数据完整性
- 重建失效数据盘的副本数据
DataNode 向 NameNode 周期上报失败时,NameNode 发起副本重建动作以恢复丢失副本
- 集群数据均衡
- 元数据可靠性保证
日志机制操作元数据,同时元数据放在主备 NameNode 上 快照机制保证数据误操作时,能及时回复数据
- 安全模式
当数据节点故障,硬盘故障时,只能读,不能写,防止故障扩散
其他特性
- 空间回收机制,副本数动态设置机制
- 数据组织:数据存储以块为单位,存储在操作系统的HDFS文件系统上
- 访问方式:提供 Java API、HTTP、Shell 方式访问 HDFS 数据
HDFS 3.0 新特性
- 支持纠删码
检错码:检测错误 纠错码:检测并纠正错误 纠删码:检测纠正错误,并在一定程度上恢复被删除的数据。替代数据副本机制,以更小的空间实现相同的功能
- 基于 HDFS 路由器的联合
- 支持多个 NameNode
- DataNode 内部添加了负载均衡
Disk Blancer
HDFS 数据读写
数据读取流程
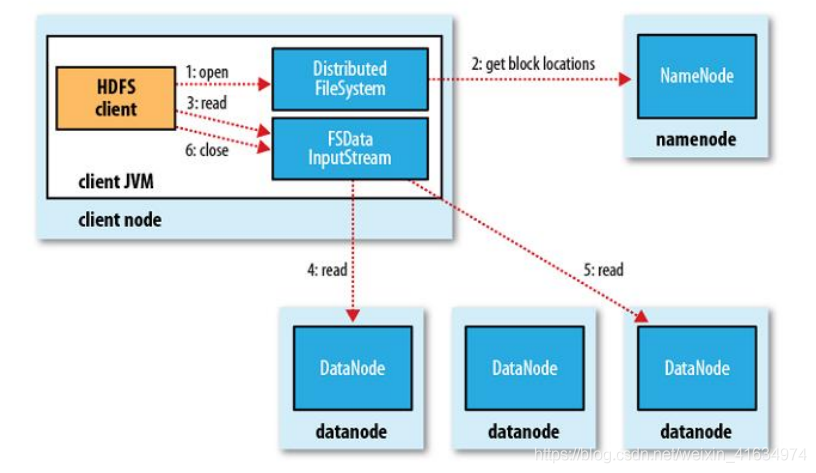
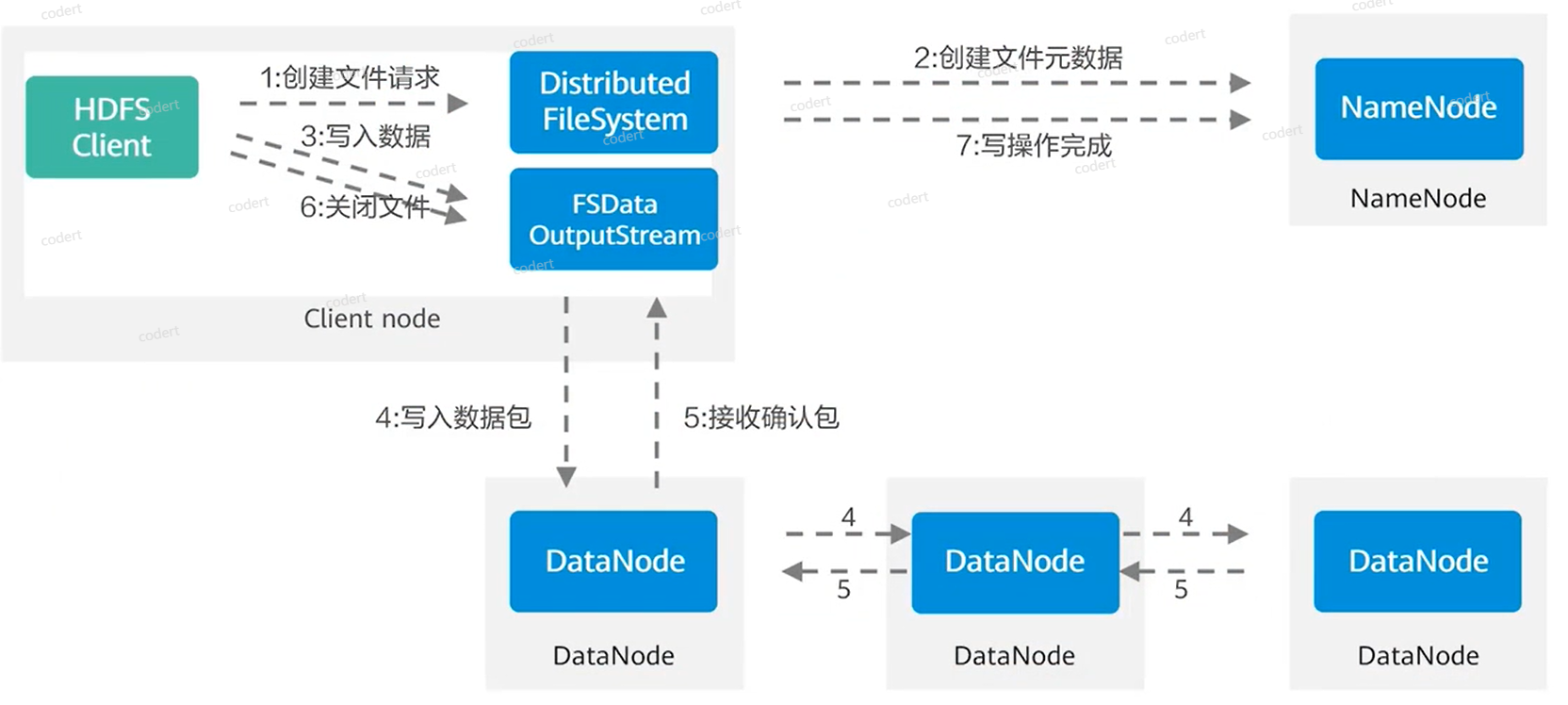
数据写入流程
Zookeeper
- Zookeeper 分布式 服务框架主要用来解决分布式应用中经常遇到的一些数据管理问题,提供分布式、高可用性的协调服务能力
- 安全模式下 Zookeeper 依赖于Kerberos和 LdapServer 进行安全认证
- 作为底层组件广泛被上层组件使用并依赖,如
Kafka、HDFS、HBase、Storm等
Zookeeper 架构 - 模型
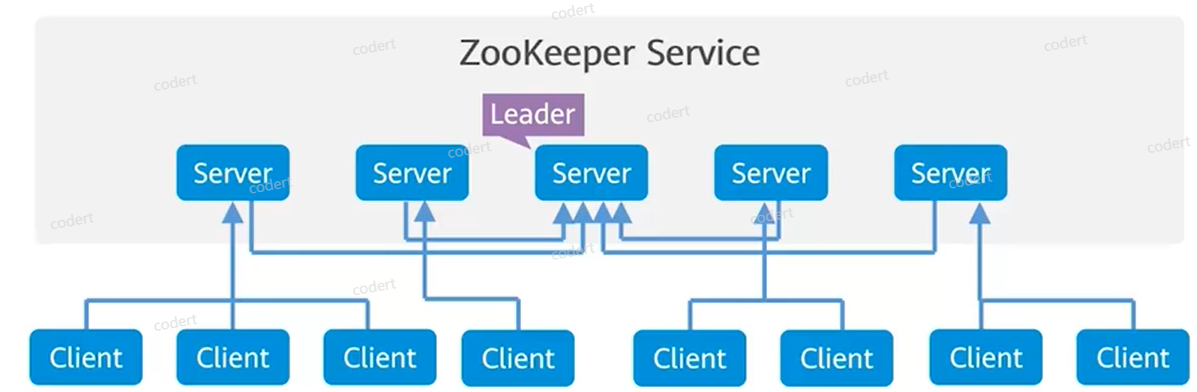
- Zookeeper 集群由一组 Server 节点组成,这组节点只存在一个 Leader 节点,其他节点都为 Follower
- 启动时选举 Leader
- 使用自定义原子消息协议,保证整个系统节点数据的一致性
- Leader 节点在接收到数据变更请求后,先写磁盘再写内存
Zookeeper 架构 - 容灾能力
- Zookeeper 能够完成选举即能正常对外提供服务
- 选举时,当某一个实例获得了半数以上的票数时,则 Leader
- 对于 n 个服务的实例,n 可能是奇数或偶数
- 当 n 为奇数时,假定 n = 2x + 1;则成为 Leader 的节点需要 x+1 票,容灾能力为 x
- 当 n 为偶数时,假定 n = 2x + 2;则成为 Leader 的节点需要 x+2 票,容灾能力大于 x
Zookeeper 关键特性
- 最终一致性:无论哪个Server,对外展示都是同一个视图
- 实时性:保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务失效的信息
- 可靠性:一条消息被一个 Server接受,它被所有 Server 接受
- 等待无关性:慢的或者失效的 client 不会干预快速的 client 请求,使得每个 client 都能有效地等待
- 原子性:更新只能成功或者失败,没有中间状态
- 顺序一致性:客户端所发送的更新会按照它们被发送的顺序进行应用
Zookeeper 常用命令
- 调用 Zookeeper 客户端,执行命令:
zkCli.sh -server 172.16.0.1:24002 - 创建节点:
create /node - 列出所有节点子节点:
ls /node - 创建节点数据:
set /node data - 获取节点数据:
get /node - 删除节点:
delete /node - 删除节点及所有子节点:
deleteall /node
Hive
Apache Hive 数据仓库软件:
- 有助于使用SQL读取,写入和管理驻留在分布式存储中的大型数据集
- 可以将结构投影到已经存储的数据上
- 提供命令行工具和 JDBC 驱动程序将用户连接到 Hive
Hive 概述
Hive 简介
Hive 是基于 Hadoop 的数据仓库软件,可以查询和管理 PB 级别的分布式数据,有如下特性:
- 灵活方便的ETL(extract/transform/load)
- 支持Tez,Spark等多种计算引擎
- 可直接访问HDFS文件以及HBase
- 易用易编程
Hive 应用场景
- 数据挖掘(用户行为分析、兴趣分区、区域展示)
- 非实时分析(日志分析、文本分析)
- 数据汇总(点击数、流量统计)
- 数据仓库(数据抽取、数据加载、数据转换)
Hive 与传统数据仓库比较
| Hive | 传统数据仓库 | |
|---|---|---|
| 存储 | HDFS,无限扩展的可能 | 集群存储,存在容量上限 |
| 执行引擎 | 默认Tez | 可选择更高效算法查询,或执行更多的优化措施提高速度 |
| 使用方式 | HQL | SQL |
| 灵活性 | 元数据独立于数据存储之外,解耦元数据和数据 | 低,数据用途单一 |
| 分析速度 | 计算依赖于集群规模,大数据量下远快于普通仓库 | 数据量小时非常快,数据量大时急剧下降 |
| 索引 | 效率低 | 高效 |
| 易用性 | 需要自行开发应用模式,灵活性高,易用性低 | 集成一套成熟的报表解决方案 |
| 可靠性 | 数据存储在HDFS,可靠性高,容错高 | 可靠性低,一次查询失败重新开始,数据容错依赖于硬件Raid |
| 依赖环境 | 依赖硬件较低 | 依赖高性能的商业服务器 |
| 价格 | 开源 | 商用比较昂贵 |
Hive 的优点
- 高可靠、高容错(
HiveServer采用集群模式、双MetaStore、超时重试) - 类SQL(类似SQL语法,内置大量函数)
- 可扩展(自定义存储、自定义函数)
- 多接口(Beeline、JDBC、ODBC、Python、Thrift)
Hive 功能与架构
Hive 架构
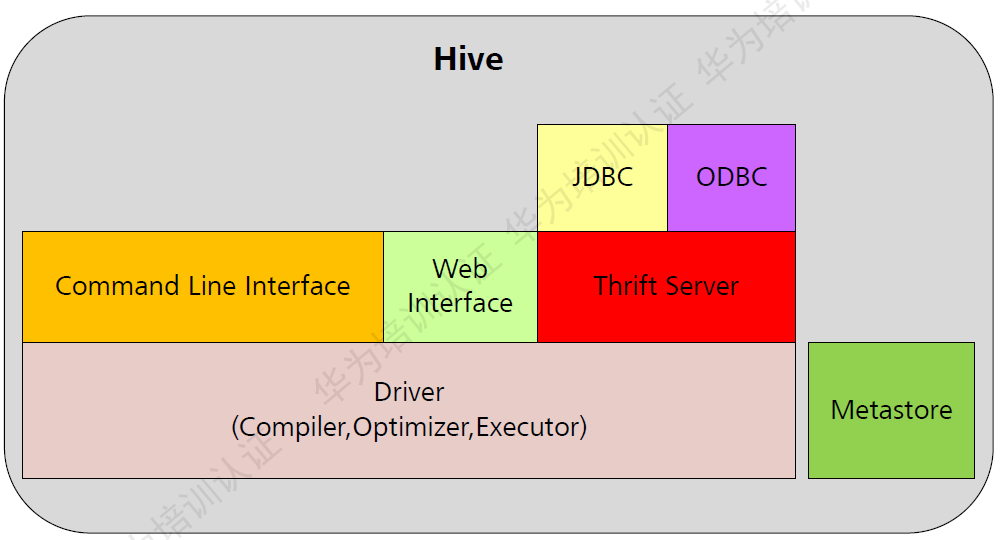
Hive 运行流程
- 客户端提交HQL
- Tez执行查询
- Yarn为集群中的应用程序分配资源,并为Yarn队列中的Hive作业启用授权
- Hive 根据表类型更新HDFS或Hive仓库中的数据
- Hive通过JDBC连接返回结果
Hive 数据存储模型
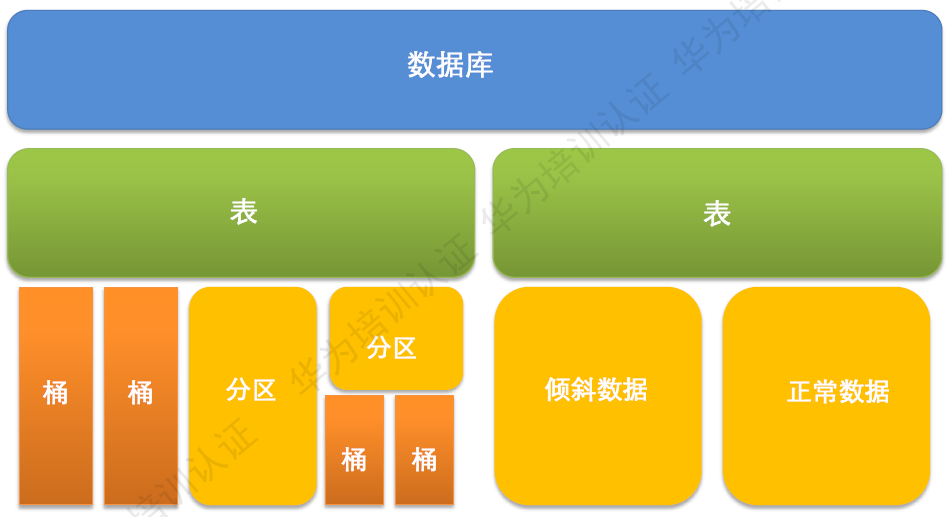
分区
数据表可以按照某个字段的值划分分区
- 每个分区都是一个目录
- 分区数量不固定
- 分区下可再有分区或桶
桶
数据可以根据桶的方式将不同的数据放入不同的桶中
- 每个桶是一个文件
- 建表时指定桶个数,桶内可排序
- 数据按照某个字段的值,Hash后放入某个桶中
托管表和外部表
- 默认创建托管表,Hive 会将数据移动到数据仓库目录
- 创建外部表,这时会到仓库目录以外的位置访问数据
- 如果所有的处理都由Hive完成,建议使用托管表
- 如果要用Hive和其他工具处理同一数据集,建议使用外部表
| 托管表 | 外部表 | |
|---|---|---|
| CREATRE/LOAD | 数据移动到仓库目录 | 数据位置不移动 |
| DROP | 元数据和数据一起删除 | 只删除元数据 |
Hive 内置函数
- 数学函数:round()、floor()、abs()、rand() 等
- 日期函数:to_date()、month()、day() 等
- 字符串函数:trim()、length()、substr() 等
- 用户自定义函数
Hive 基本操作
Hive 使用方式
Running HiveServer2 and Beeline
|
|
Running Hcatelog
|
|
Running WebHCat(Templeton)
|
|
DDL 操作
|
|
DML 操作
|
|
DQL 操作
|
|
HBase
HBase 概述
HBase 简介
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统
- 适合存储大表数据,并对大表数据的读写可以达到实时级别
- 利用Hadoop HDFS 作为其文件存储系统
- 利用Zookeeper 作为协同服务
HBase 与 RDB 对比
| HBase | RDB | |
|---|---|---|
| 数据索引 | 只有一个索引——行键,通过行键访问或扫描 | 复杂的多个索引 |
| 数据维护 | 更新时版本迭代,保留旧版本 | 更新时替换 |
| 可伸缩性 | 灵活水平扩展 | 难以横向扩展,纵向扩展有限 |
HBase 应用场景
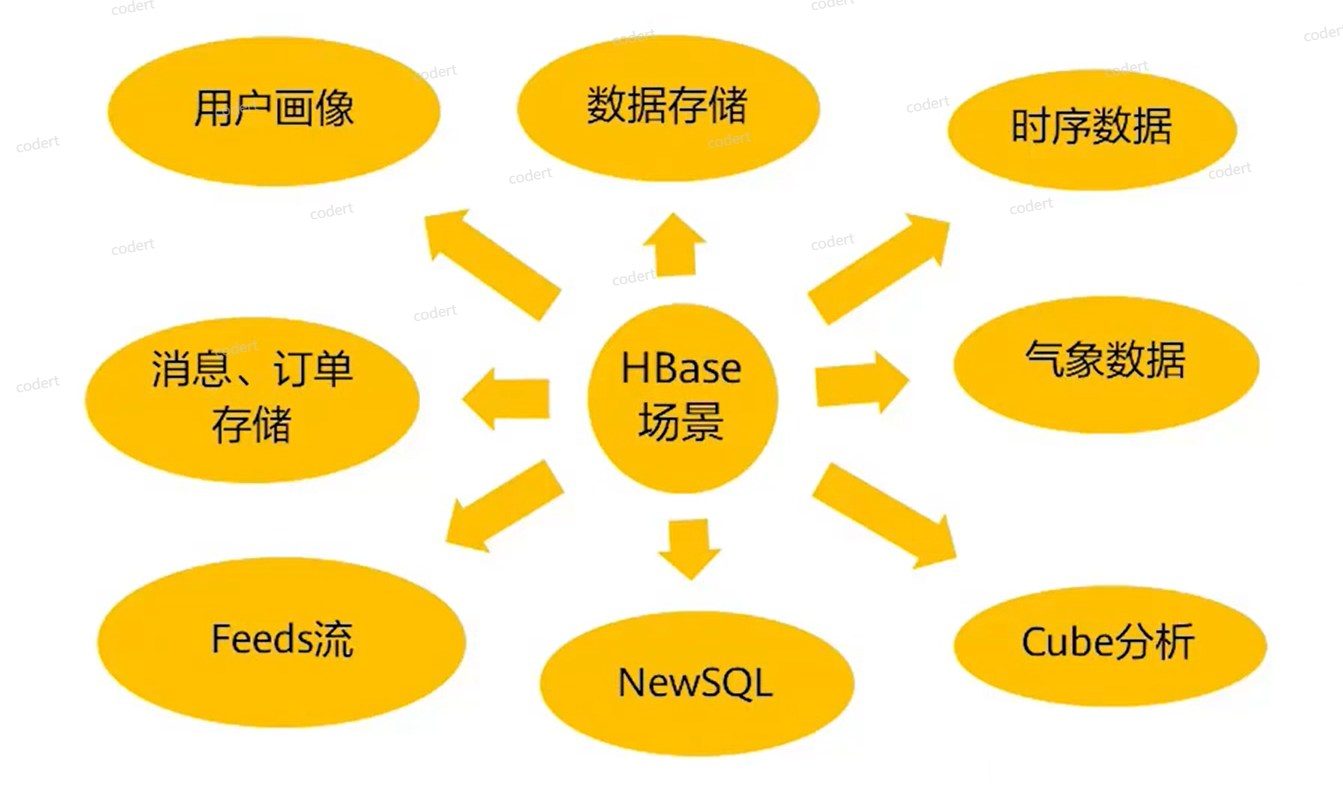
适合具有如下需求的应用:
- 海量数据
- 不需要完全拥有 ACID 特性
- 高吞吐量
- 海量数据中随机读取
- 很好的伸缩能力
- 同事处理结构化和非结构化数据
HBase 功能架构
HBase 数据模型
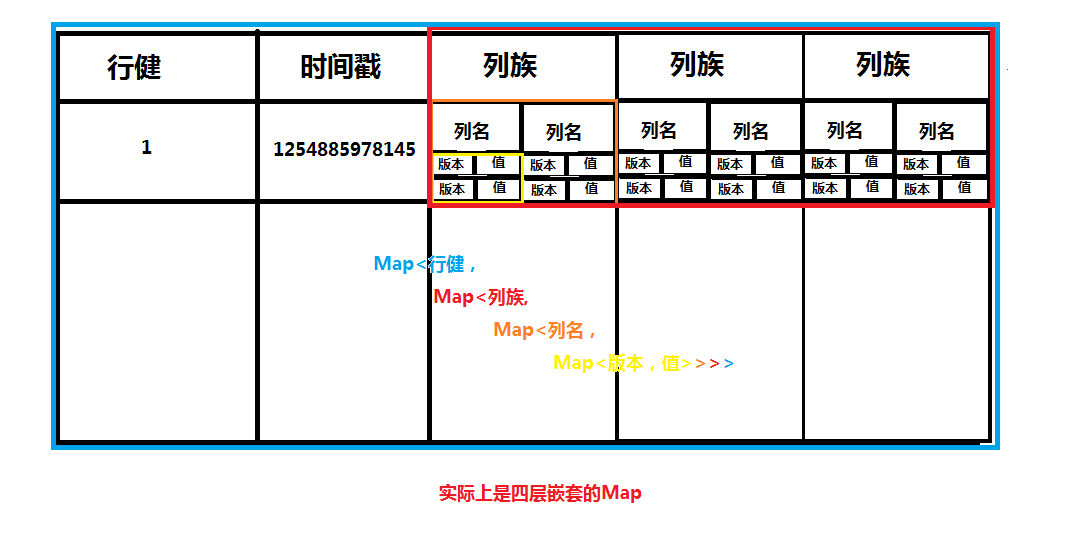
- 以表的方式在HBase中存储
- 行和列构成,所有的列从属一个列族
- 行列交叉点称为 cell,随版本变化,不可分割,没有类型(都是byte[])
- 行键也是字节数组,任何东西都可以保存进去
- HBase的表是按 key 排序的,排序方式针对字节
- 所有的表都必须要有主键——key
HBase 架构
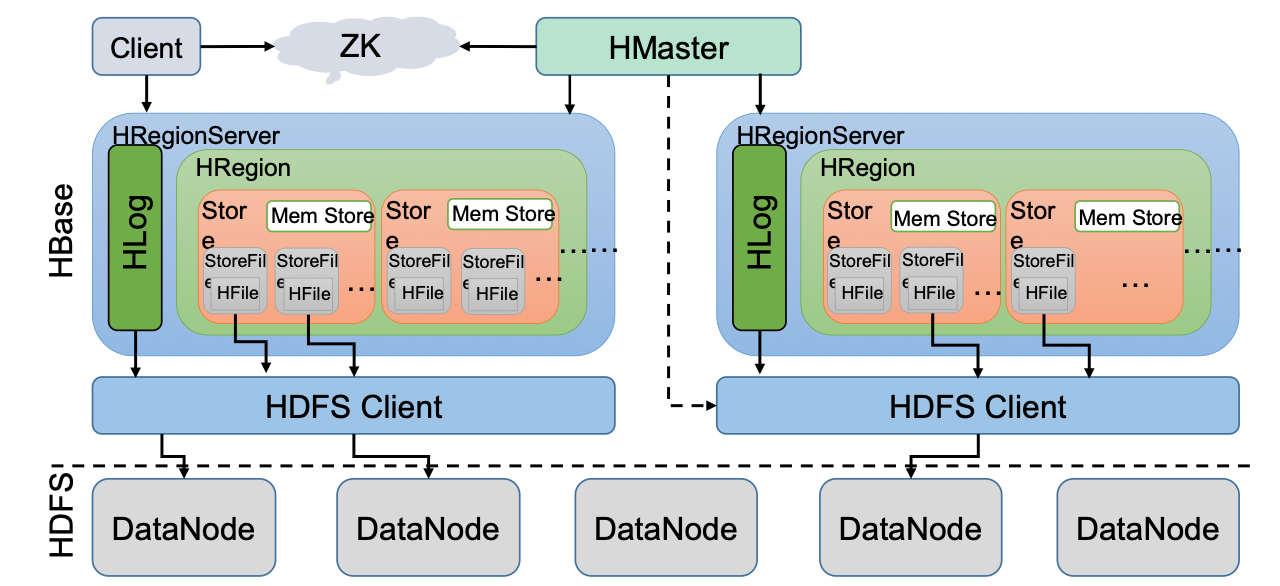
主要的功能组件
- 库函数:链接到每个客户端
- 客户端不是直接从 Master 上获取数据,而是获得 Region 的位置信息后,直接从
HRegionServer上读取数据 - 客户端不依赖 Master,通过 Zookeeper 来获取 Region 位置信息,大多数客户端从不与 Master 通信
- 客户端不是直接从 Master 上获取数据,而是获得 Region 的位置信息后,直接从
Master主服务器- 管理和维护 HBase 表的分区信息,维护 Region 服务器列表,分配 Region,负载均衡
HRegionServer服务器- 存储和维护分配给自己的 Region,处理来自客户端的读写请求
表结构
- Table
- Region(初始只有一个,后不断分裂)
- Store(存储每一个列族)
- MemStore(临时存储Region)
- StoreFIle(存储Region)
- Block(存储到HDFS)
- Store(存储每一个列族)
- Region(初始只有一个,后不断分裂)